From blockchain to DAG (IV) GHOSTDAG Protocol of MeerDAG Consensus

In the last article, we focused on how the SPECTRE consensus protocol outputs blocks, how to deal with conflicting transactions, generate trusted transaction sets, and how to prevent network attacks. SPECTRE is a blockDAG protocol that supports fast confirmation, however, SPECTRE can only do a relative ordering of conflicting transactions (to judge the order of conflicting transactions), and cannot do an absolute ordering of all blocks. Therefore, the Qitmeer team introduced the more sequential GHOSTDAG protocol, which can do a linear ordering of the whole ledger and meet the blockchain network’s requirement of sequential order of the ledger.
First of all, before designing the MEERDAG protocol, we must assume that the entire node network meets the major premise of decentralization, that is, more than 50% of the nodes are honest and reliable, and can effectively guarantee the security of the ledger. However, even if most nodes obey the mining rules, there is no guarantee that every node is honest and reliable. If there are nodes with malicious intentions, they can record some fake transactions and block the blocks of other good nodes to achieve the purpose of tampering with transactions. If so, how can we distinguish which blocks are from good nodes and which are from bad nodes?
Therefore, the Qitmeer team relies on the GHOSTDAG protocol to determine the connectivity to judge the red and blue blocks of the block graph network. Simply put, connectivity between the blocks generated by malicious nodes and the blocks generated by honest nodes is lower, and conversely the connectivity between the blocks generated by honest nodes will be higher.
Secondly, we then set the voting mechanism. Like Bitcoin, Qitmeer adopts the POW consensus for block generation, and uses hashrate to vote. But the difference is that the ledger consensus standard is no longer to see which chain is the longest, but to see which subset in the graph contains the most interconnected blocks of honest nodes and meets the requirement of k value. I call the subset that satisfies the k-value requirement a k-cluster.
Next, we can design the classification algorithm to distinguish the blocks of good nodes and bad nodes. Since the block set of good nodes is the largest k-cluster subset in the graph, the remaining part must come from bad nodes. So the core of the algorithm is to find the largest k-cluster subset.
Finally, all blocks in the block graph are linearly sorted by topological rules. In principle, the honest blocks are arranged first, and then the dishonest blocks, so as to establish a sequential order for all blocks. Finally, block rewards are given to honest blocks, but dishonest blocks are not necessarily malicious blocks, and they also participate in the bookkeeping process, so can get block transaction fees.
The GHOSTDAG protocol is mainly divided into two parts: 1. Determine honest blocks and malicious blocks by voting, 2. Linearly sort the blocks. Both of them will be explained one by one below. Here we reiterate the premise that the ledger consensus is effective: most nodes in the network are honest. We do not consider such a malicious attack that concentrates more than 51% of the hashrate, because such an attack will work no matter what ledger consensus is used.
GHOSTDAG Voting Principles
As << https://qitmeer.medium.com/from-blockchain-to-dag-iii-ea7440df19f1 >> ,we can know that during a “double spend” attack, the attack block is hardly associated with the block generated by the honest node before it is released, because at this stage, the honest blocks are not aware of the existence of the attacking blocks, so they will not refer to them. In a censorship attack, blocks produced by attacking nodes have a similar tendency: they are not associated with the blocks generated by the honest node that contain “conflicting transactions”.
Taken together, these malicious attacks have a remarkable feature: the connectivity between the blocks generated by malicious nodes and the blocks generated by honest nodes is relatively low, whereas the connectivity between blocks generated by honest nodes will be relatively high. The voting principle of GHOSTDAG is based on this theory, voting by judging the connectivity between different blocks. In order to describe the voting process clearly, we will introduce several related concepts first, see Picture 1.

Source: Yonatan Sompolinsky, Shai Wyborski, and Aviv Zohar,⟪ PHANTOM and GHOSTDAG:A Scalable Generalization of Nakamoto Consensus ⟫
Take block H as an example: past(H)={Genesis, C, D, E}–the past blocks that point directly or indirectly to H before H was created, future(H)={J,K,M}-- Directly or indirectly point to future blocks of H after H is created. anticone(H)={B, F, I, L}–blocks other than past(H) and future(H), these blocks have no direct or indirect relationship with H. How to sort these blocks is the main difficulty of DAG consensus. tips(G)={J, L, M}–leaf blocks, or end blocks; these blocks will become block header references for new blocks.
The fork coefficient k, intuitively, this is a number that describes the number of forks allowed by the network. Strictly speaking, k is defined as a propagation parameter, which is used to describe the phenomenon of propagation delay. In << https://qitmeer.medium.com/from-blockchain-to-dag-i-9e2180ec676d >> , we mentioned that in the actual process, the phenomenon of network delay cannot be avoided, and secondly, this delay will lead to forks. If forks are to be avoided, it is necessary to ensure that no new blocks are generated within the network delay period Δt, that is, k=0. The definition of the k value is very important. If the k value is too large, it will cause too many forks and reduce the security of the network; if it is too small, it will limit the network performance and make the TPS lower. For example, the blockchain is a k=0 network. The degree of connectivity is determined by the value of k, and the degree of connectivity of a block must meet the requirements of the subset of the largest k-cluster, as shown in Picture 2.

Source: Yonatan Sompolinsky, Shai Wyborski, and Aviv Zohar,⟪ PHANTOM and GHOSTDAG:A Scalable Generalization of Nakamoto Consensus ⟫
How to judge whether a block is generated by an honest node? First find the anticone set of this block. If the number of intersections between this set and the subset S of k-cluster of DAG is less than or equal to k, then this block is generated by an honest node and will be added to the subset S. Otherwise, Blocks generated by attacking nodes will not be added to the set. After iterating the whole process to filter all the blocks, all blocks judged to be honest will be added to this subset S. At this time, S is called the largest k-cluster subset, which is written as MSCk, and all the blocks in the set will be counted in the ledger.

Source: Yonatan Sompolinsky, Shai Wyborski, and Aviv Zohar,⟪ PHANTOM and GHOSTDAG:A Scalable Generalization of Nakamoto Consensus ⟫
As shown in Picture 3, the blocks generated by honest nodes are marked in blue, and the blocks generated by attacking nodes are marked in red. All sets that meet the requirements of Picture 2 belong to the largest subset of the 3-cluster, that is, all blue blocks belong to MSC3. Let’s verify whether such a block division can meet the above requirements. The blue block takes G as an example: anticone(G)={B, F, I, E, H, K}; the intersection of anticone(G) and the blue block is B, F, I, a total of 3, satisfying less than or equal to the requirement of the k value (the k value of the DAG is 3), so G is a block generated by an honest node and can be counted to the ledger.
All red blocks also conform to this principle. According to this rule, all the blocks are filtered in order to judge and exclude the attack block.
The principle behind this is simple: the anticone(X) of block X refers to the set of blocks unrelated to X. If anticone(X) has more intersections with blocks generated by honest nodes, it means that the connectivity between X and honest blocks is lower. Here, adding a limit value k to the connectivity is used as a judgment criterion. If the number of intersections between anticone(X) and the honest block is higher than the k value, it means that the connectivity between the X block and the honest block is low, and X will be judged as an attack block; otherwise, it means that the connectivity between X and the honest block is high , X is considered an honest block.
Linear Sorting
The definition of Topological Sort: To perform topological sorting on a Directed Acyclic Graph (DAG for short) G is to arrange all the vertices in G into a linear sequence, so that any pair of vertices u and v in the graph, if the edge < u , v > ∈ E ( G ), then u appears before v in the linear sequence. Usually, such a linear sequence is called a sequence that satisfies the topological order, referred to as a topological sequence.
Simply put, a total order on a set is obtained from a partial order on a certain set, this operation is called topological sort.
This process can be summed up in three key points:
1. Directed acyclic graph;
2. Each point in the sequence can only appear once;
3. For any pair of u and v, u is always before v (the two letters here represent the two endpoints of a line segment, u represents the starting point, and v represents the end point);
According to the principle of judging the red and blue blocks, after finding the MSCk subset, the next step is to perform linear sorting in the set. The sorting principle is the same as that of topological sort, as shown in Picture 4 for example.

Topological sorting refers to the process of arranging the vertices on the DAG into a linear sequence, and obtaining a total order of the set from a partial order on the set. The principle of sorting: first select the vertex without arrow input as the starting point, remove this vertex from the graph after each sequence is arranged, and then select the vertex without input from the removed graph as the next sequence, and so on. until the last vertex is output. It should be noted that the order of topological sorting is not unique, and there may be multiple options. For example, in picture 4, you can also choose to output f in step ( c ), and the final order is acfbde. According to this principle, one of the final output results of the DAG in Figure 3 is: A->D->C->G->B->F->I->E->J->H->K. This result can be any topological sort, but the blue blocks will be arranged first, and the red blocks will be naturally arranged behind the blue blocks due to low connectivity.
Examples of GHOSTDAG protocol applications
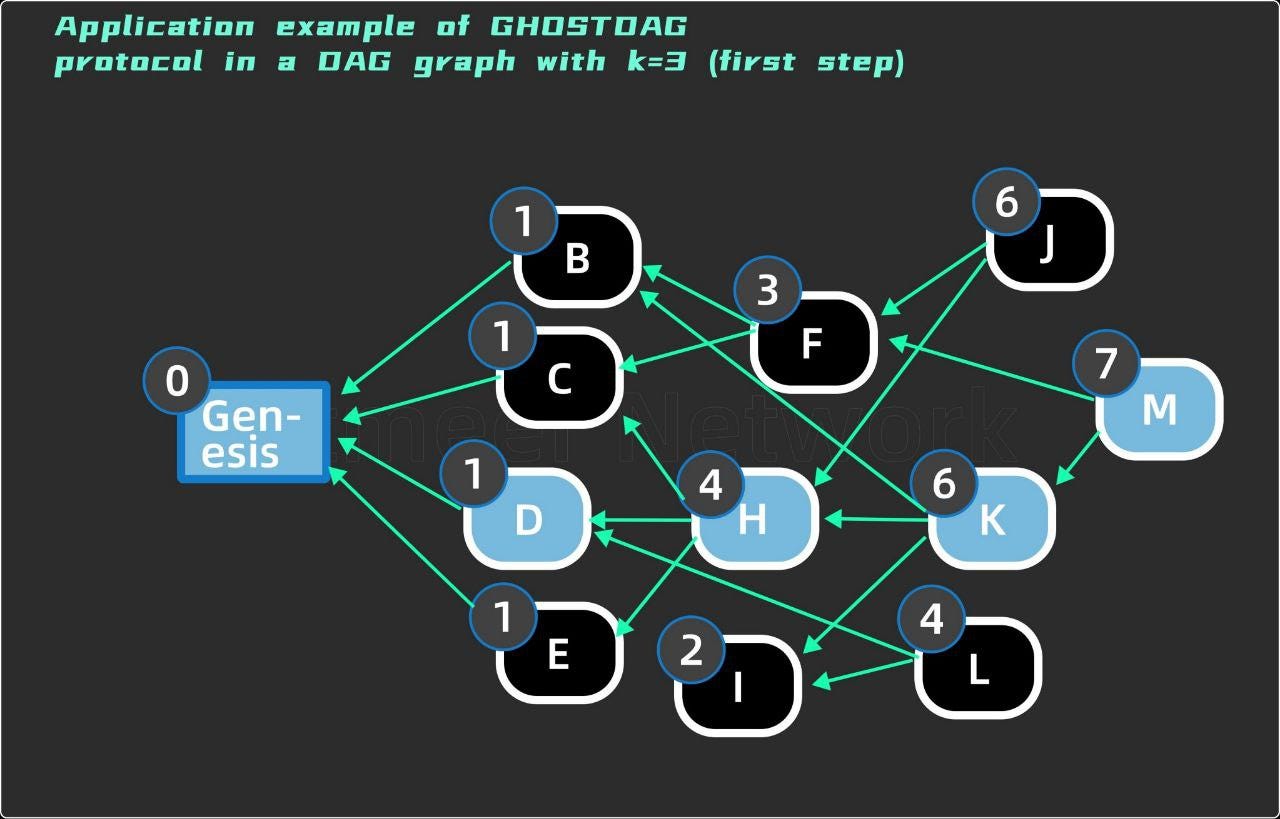
From the above, it is clear that the first step of the GHOSTDAG protocol to determine the honest blocks is the most critical and complex step. How to determine MSCk efficiently will directly affect the performance of the whole network, and a greedy algorithm is introduced here to solve this problem. First, each block is scored according to its connectivity (the number of elements in the set of block past), and the block with the largest total score is selected to form the main chain, which will form the initial subset S. The remaining blocks will be voted in order according to the order of the main chain. The principle is that the selected main chain blocks have a high degree of connectivity and can be preferentially added to the S set. In this way, the entire network will vote according to the trend of connectivity from high to low, and find the largest k-cluster subset MSCk in the fastest way. Let’s review the operation process of the GHOSTDAG protocol through an example:
Source: Yonatan Sompolinsky, Shai Wyborski, and Aviv Zohar,⟪ PHANTOM and GHOSTDAG:A Scalable Generalization of Nakamoto Consensus ⟫
The numbers in the small blue circles in the figure represent the connectivity score of each block X, and the score is equal to the number of blocks in each block past(X). According to the rules of the greedy algorithm, I need to select a path with the highest total score, first select the block M with the highest score, and then filter all past blocks past(M) of M in turn. If two blocks have equal scores, a path is randomly selected, and the final selected main chain path is shown in the blue block in picture 5: Gensis->D->H>K->M, the initial S ={Genesis, D, H, K, M}. Next, verify: D block past(D) only has the genesis block, anticone (Genesis) is an empty set, and the number of intersections with S is 0≤3, so the genesis block satisfies the 3-cluster subset requirement, Marked with a blue border.

Source: Yonatan Sompolinsky, Shai Wyborski, and Aviv Zohar,⟪ PHANTOM and GHOSTDAG:A Scalable Generalization of Nakamoto Consensus ⟫
The second step comes to block H. In addition to the genesis block, past (H) also has C, D, and E. Find the anticone sets of these three blocks and determine whether the number of intersections between them and S is less than Equal to the value of k, where the value of k is 3. anticone©={B, D, E, I, L}; the intersection with S is {D}, and the number of intersections is 1≤3. anticone(D)={B, C, F, E, I, L}; The number of intersections with S is 0≤3. anticone(E)={B, C, D, F}; The intersection with S is {D}, and the number of intersections is 1≤3. Therefore, these three blocks are added to the subset of the 3-cluster. At the end of this step, the subset is updated to S={Genesis, D, H, K, M, C, E}, which is marked with a blue border in Picture 6.
Source: Yonatan Sompolinsky, Shai Wyborski, and Aviv Zohar,⟪ PHANTOM and GHOSTDAG:A Scalable Generalization of Nakamoto Consensus ⟫
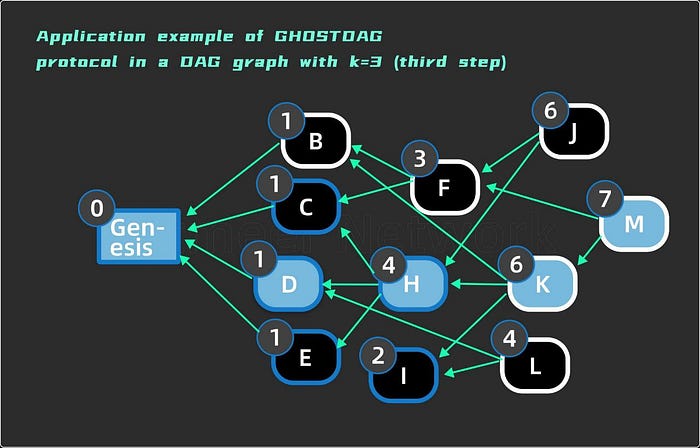
The third step is to access block K. In past(K), it is necessary to determine whether H, I, and B are to be added to subset S. anticone(H)={B, F, I, L}; The number of intersections with S is 0≤3. anticone(I)={B, C, D, H, F, J}; the intersection with S is {C, D, H}, and the number of intersections is 3≤3. So at the end of this step, H and I are also added to S, which is marked with a blue border in Figure 7. anticone(B)={C, D, E, H, I, L}; the intersection with S is {C, D, E, H}, and the number of intersections is 4>3. Therefore, B does not meet the subset condition of 3-cluster, and will not be added to the subset, and B is judged as a block generated by a malicious node. At the end of the third step, the subset is updated to S={Genesis, D, H, K, M, C, E, I}.

Source: Yonatan Sompolinsky, Shai Wyborski, and Aviv Zohar,⟪ PHANTOM and GHOSTDAG:A Scalable Generalization of Nakamoto Consensus ⟫
The fourth step is to access the block M. In the past(M), it is necessary to judge whether F and K are to be added to the subset S. anticone(K)={F, J, L}; The number of intersections with S is 0≤3. anticone(F)={D, H, K, E, I, L}; the intersection with S is {D, H, K, E, I}, and the number of intersections is 5>3. So block K is added to the subset, but F is not. Here update the subset S={Genesis, D, H, K, M, C, E, I}.

Source: Yonatan Sompolinsky, Shai Wyborski, and Aviv Zohar,⟪ PHANTOM and GHOSTDAG:A Scalable Generalization of Nakamoto Consensus ⟫
The last step is to access a virtual block V that has not been officially generated. The block referenced by V is tips(G), which means that past(V) is all existing blocks, which are represented by dotted lines in Picture 9. Continue to judge whether J, M, L are added to the subset. anticone(M)={J, L}; The number of intersections with S is 0≤3. anticone(L)={B, C, F, J, M, H, K}; the intersection with S is {C, M, H, K}, the number of intersections is 4>3, L does not belong to 3-cluster subset of. Anticone(J)={M, K, I, L}; the intersection with S is {M, K, I}, and the number of intersections is 3≤3; it stands to reason that J should be added to the subset, but this will cause anticone( I) The final intersection with the largest subset MSC3 becomes {C, D, H, J}, the number of intersections is 4>3, and I cannot be added to the subset set. This will give a result that contradicts the previous step, so J cannot be added to the subset here. Finally, the subset MSC3={Genesis, D, H, K, M, C, E, I} of the largest 3-cluster of this DAG graph.
Next, we start sorting: first perform topological sort on the blue blocks in MSC3: Genesis->D->E->C->I->H->K->M. After sorting the black border blocks that are not in MSC3 and adding them to the arrangement of the blue blocks, the final sort is Genesis->D->E->C->I->H->K->M->B ->F->L->J. Transactions are automatically sorted in the order in which they appear within each block, and the linear sorting of the entire network is now complete.
DAG structure difficulty adjustment
The definition of the irrelevant block limit value (k value) is very important, because the level of connectivity is determined by the k value, if the k value is too large, there will be too many forks, resulting in slow confirmation time, and the proportion of red blocks will also increase, which reduces the security of the network; if it is too small, it will limit the network performance and make the TPS lower.
How to balance network efficiency and security has become a problem in front of Qitmeer.
The MEERDAG structure difficulty adjustment is mainly performed by controlling the block generation time and the irrelevant block limit (k-value): (1) Let the blocks be generated according to the target time (2) Let the number of concurrency on each difficulty follow the preset parameters according to the concurrency limit.
According to the standard block size of 1M, the current Internet environment, it takes roughly 10 seconds to broadcast to more than 90% of the nodes, and generally within 15 seconds the block can be spread to most nodes. For nascent networks, with fewer block transactions and a more concentrated distribution of nodes, 15 seconds is enough to reach almost all nodes. But there are always exceptions that cause nodes to not synchronize blocks within 15 seconds, we call these unsynchronized blocks collectively as failed blocks. That is, the red blocks, the other normal blocks are naturally blue blocks.
Control the irrelevant block limit value (k value) by setting the parameters affected by the concurrency limit, block production rate, security level, and block propagation time. The block propagation time is the maximum time for the block to propagate to the whole network, which ensures fault tolerance.
The security level refers to the probability that an honest block will be judged as an invalid block, that is, a red block, or it can also be understood as the fault tolerance of the network. The block rate is the number of blocks generated per second. The security level and propagation time can be regarded as the physical properties of the network, which can be empirical values or calculated, and can be regarded as constants, but the block rate is a parameter of the network, which can be adjusted according to the needs of network operations.
Qitmeer judges the best block generation time and irrelevant block limit value (k value) by setting and testing different parameters of block generation rate, security level, and block propagation time. Finally, it is found that the security level be 1%, and the block propagation time The setting time be 30 seconds and the block rate be 1/30 (blocks/second) is more suitable.
~/github.com/forchain/AnticoneSize (master*) $ ./AnticoneSize -rate 0.03333333333_delay:15 _rate:0.03333333333 _security:0.01 expect:0.9999999999 coef:0.3678794412082303
k=0 sum=0.6321205587917698
k=1 sum=0.2642411176203274
k=2 sum=0.08030139705300021
k=3 sum=0.01898815687002247
k=4 sum=0.0036598468258108655
The test results of the above parameters show that the probability of irrelevant blocks exceeding 4 blocks is only 0.366%, and the probability of exceeding 1 block is only 26.42%, that is, in most cases, there is either one chain or only one sidechain block. This can first ensure that the k value remains within a controllable range most of the time, so that the proportion of red blocks can be effectively reduced, and it is also for the consideration of economic model design and ledger expansion, and when the subsequent ecological prosperity of the chain, it can also significantly improve the network performance by reducing the block generation time to guarantee the landing of business scenarios with high demand for performance.
Summary
When k=0, the GHOSTDAG rule is expressed as the longest chain consensus of Bitcoin. Like the SPECTRE protocol, the GHOSTDAG protocol is an extension of the longest chain consensus. The difference from SPECTRE is that GHOSTDAG, which can be strictly sorted, is suitable for networks with linear sorting requirements, and at the same time solves the problem of weak activity of SPECTRE protocol transactions.
Qitmeer is one of the few high-performance public chains that adopts the blockDAG hybrid consensus of the two protocols of SPECTRE+GHOSTDAG. Although the security of these two protocols has been verified mathematically, they are limited by the difficulty of implementation at the code level and blockDAG Theoretical research is slow, and there are not many projects that have been implemented. For example, Conflux, Kaspa, Qitmeer, Xdag and other projects are the technology pioneers of blockDAG.
In 2018, we decided to adopt the blockDAG consensus. At the beginning of 19, we designed the MEERDAG technology prototype. After 18 months of real hashrate testing, we continuously optimized the MEERDAG consensus and continuously evolved the mining algorithm. Finally, the main network was officially launched on September 30, 2021.
At present, Qitmeer Network and Birmingham City University have jointly established the Meer Labs blockchain technology research laboratory, focusing on the academic research of blockchain underlying technology and the development direction of blockchain new media. Experts and scholars in the DAG field are gathered in the laboratory to conduct in-depth research on blockchain technology research and development, commercial applications, and industrial strategies. We look forward to further development in the future theoretical research of blockDAG and the expansion of Qitmeer ecology.